机器学习掌握海量数据集算法突破艾字节屏障
机器学习算法通过识别海量数据集的关键特征并将其划分为不会阻塞计算机硬件的可管理批次,展示了处理超出计算机可用内存的数据的能力。该算法由洛斯阿拉莫斯国家实验室开发,在橡树岭国家实验室Summit(世界第五快的超级计算机)上进行测试运行时,创下了分解巨大数据集的世界纪录。
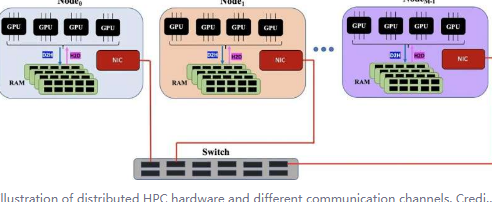
这种高度可扩展的算法在笔记本电脑和超级计算机上同样高效,它解决了阻碍处理来自癌症研究、卫星图像、社交媒体网络、国家安全科学和研究等数据丰富的应用程序的信息的硬件瓶颈。
洛斯阿拉莫斯国家实验室的计算物理学家IsmaelBoureima表示:“我们开发了非负矩阵分解方法的‘内存不足’实现,使您能够在给定硬件上分解比以前更大的数据集。”Boureima是《超级计算杂志》上关于破纪录算法的论文的第一作者。
“我们的实施只是将大数据分解为可以使用可用资源进行处理的较小单元。因此,它是跟上呈指数增长的数据集的有用工具。”
“传统的数据分析要求数据符合内存限制。我们的方法挑战了这一概念,”洛斯阿拉莫斯机器学习科学家、该论文的合著者ManishBhattarai说。
“我们引入了一种内存不足的解决方案。当数据量超过可用内存时,我们的算法会将其分解为更小的段。它一次处理一个段,将它们循环进出内存。这种技术使我们拥有有效管理和分析超大数据集的独特能力。”
Boureima表示,现代异构高性能计算机系统的分布式算法可以在小到台式计算机的硬件上使用,也可以在像Chicoma、Summit或即将推出的Venado超级计算机这样大型和复杂的硬件上使用。
“问题不再是是否可以分解更大的矩阵,而是分解需要多长时间,”布雷马说。
洛斯阿拉莫斯实施利用GPU等硬件功能来加速计算和快速互连,以在计算机之间高效地移动数据。同时,该算法有效地同时完成多个任务。
非负矩阵分解是洛斯阿拉莫斯SmartTensors项目下开发的高性能算法的另一部分。
Boureima说,在机器学习中,非负矩阵分解可以用作无监督学习的一种形式,从数据中提取意义。“这对于机器学习和数据分析非常重要,因为该算法可以识别数据中对用户具有特殊意义的可解释的潜在特征。”
破纪录的跑步
在洛斯阿拉莫斯团队破纪录的运行中,该算法使用25,000个GPU处理了340TB的密集矩阵和11EB的稀疏矩阵。
这篇新论文的合著者、洛斯阿拉莫斯大学的理论物理学家博伊安·亚历山德罗夫(BoianAlexandrov)表示:“据我们所知,我们正在达到艾字节分解的水平,这是其他人尚未做到的。”他领导了开发SmartTensors人工智能平台的团队。
分解或分解数据是一种专门的数据挖掘技术,旨在提取相关信息,将数据简化为可理解的格式。
Bhattarai进一步强调了他们算法的可扩展性,并表示:“相比之下,传统方法经常遇到瓶颈,主要是由于计算机处理器与其内存之间的数据传输滞后。”
“我们还表明你不一定需要大型计算机,”布雷马说。“如果您能负担得起的话,扩展到25,000个GPU是很棒的,但我们的算法在台式计算机上将非常有用,可以处理您以前无法处理的事情。”
免责声明:本文由用户上传,与本网站立场无关。财经信息仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。 如有侵权请联系删除!
-
作为A股市场中极具代表性的黄金珠宝行业龙头企业,作为中国历史最悠久的珠宝品牌之一,老凤祥(股票代码:600612)...浏览全文>>
-
宝子们,杭州 房子装修完成啦!这次要给大家分享几家设计超赞的装修公司哦。它们各具特色,从空间规划到风格...浏览全文>>
-
欲筑室者,先治其基。在上海,装修房子对于每个业主而言,都是极为关键的一步,然而,如何挑选一家值得信赖的...浏览全文>>
-
2025年以来,联通支付严格贯彻落实国家战略部署,以数字和科技为驱动,做好金融五篇大文章,履行支付为民社会...浏览全文>>
-
良工巧匠,方能筑就华居;精雕细琢,方可打造美家。当我们谈论装修公司时,选择一家靠谱可靠的公司是至关重要...浏览全文>>
-
在当今社会,随着城市化进程的高速推进,建筑垃圾的产生量与日俱增。据权威数据显示,我国每年建筑垃圾产生量超 ...浏览全文>>
-
家人们,在上海要装修,选对公司那可太重要了!古语有云:"安得广厦千万间,大庇天下寒士俱欢颜。"一个温馨的...浏览全文>>
-
近年来,新能源汽车市场发展迅猛,各大品牌纷纷推出各具特色的车型以满足消费者多样化的需求。作为国内新能源...浏览全文>>
-
近年来,随着汽车市场的不断变化和消费者需求的升级,安徽滁州地区的宝来2025新款车型在市场上引起了广泛关注...浏览全文>>
-
随着汽车市场的不断变化,滁州地区的消费者对高尔夫车型的关注度持续上升。作为大众品牌旗下的经典车型,高尔...浏览全文>>
- 安徽滁州途安L新车报价2022款,最低售价16.68万起,入手正当时
- 小鹏G7试驾,新手必知的详细步骤
- 别克GL8预约试驾,4S店的贴心服务与流程
- 安徽阜阳ID.4 CROZZ落地价全解,买车必看的省钱秘籍
- 淮北探岳多少钱 2025款落地价,最低售价17.69万起现在该入手吗?
- 安徽淮南大众CC新款价格2025款多少钱能落地?
- 淮北长安启源C798价格,最低售价12.98万起现在该入手吗?
- 安徽淮南途锐价格,各配置车型售价全解析
- 蒙迪欧试驾预约,4S店体验全攻略
- 沃尔沃XC40试驾需要注意什么
- 滁州ID.4 X新车报价2025款,各车型售价大公开,性价比爆棚
- 试驾思域,快速操作,轻松体验驾驶乐趣
- 试驾长安CS35PLUS,一键搞定,开启豪华驾驶之旅
- 天津滨海ID.6 X落地价限时特惠,最低售价25.9888万起,错过不再有
- 天津滨海凌渡多少钱?看完这篇购车攻略再做决定
- 安徽池州长安猎手K50落地价,买车前的全方位指南
- 山东济南ID.6 CROZZ 2024新款价格,最低售价19.59万起,现车充足
- 试驾海狮05EV,新手必知的详细步骤
- 生活家PHEV多少钱 2025款落地价走势,近一个月最低售价63.98万起,性价比凸显
- 奇瑞风云A9试驾,新手必知的详细步骤