全息数据存储中基于深度学习的无透镜复振幅解调
大数据时代,全球数据量呈指数级增长。众多技术的发展依赖于海量数据,也产生海量数据。数据挖掘、存储和保护变得越来越重要。传统数据存储技术的发展已经跟不上数据产生的速度,需要开发新的高密度、持久、低成本的存储方式。
传统的数据存储技术基本上是将一维数据存储在二维表面上。要突破现有技术的局限性,需要从存储维度的增加来思考。
全息数据存储似乎是一个可行的解决方案。它利用信息光编码图案和参考光编码图案之间的干涉在介质中记录全息图。读取时,仅参考光束用于从全息图衍射信息光图案。
全息数据存储技术具有三维体存储和二维数据传输的特点,能够实现更高的存储密度和更快的数据传输速度,是下一代存储技术的有力竞争者。
事实上,全息数据存储技术提出已有60年,但至今仍未得到实际应用。原因之一是传统的全息数据存储仅采用幅度调制,与全息的理论意图不符,实际达到的存储密度与理论值相去甚远。
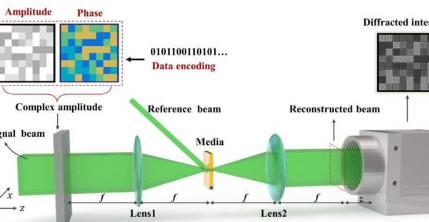
为了充分利用全息数据存储的优势,必须使用复调幅进行记录和读取。然而,技术瓶颈在于相位读取,因为相位无法通过检测器直接获得。
使用干扰读相的问题是系统不稳定,不利于实用,而传统的非干扰方法往往需要迭代计算,降低了数据传输速度。在《Opto-ElectronicAdvances》的一篇新文章中,研究人员提出利用近场衍射的强度图像,在无干扰的情况下同时、非迭代地准确读取振幅和相位信息,解决了全息数据存储复杂振幅调制的关键技术瓶颈。
该模型的核心在于使用端到端的卷积神经网络从近场衍射图案中提取高频和低频图像特征,对应于相位调制和幅度编码。在神经网络训练的基础上,建立具有泛化能力的网络,准确预测新的复振幅编码信息。
本质上,深度学习在时间维度上积累了足够多的冗余特征信息,以弥补由于无法检测空间相位而导致的维度损失问题。深度学习和全息数据存储之间有一个很好的结合点。与其他成像应用不同,由于全息数据存储的编码是可控的,这种编码先验可以用来有意识地调制编码规则,产生更多差异化的数据样本,使深度学习更高效。
福建师范大学谭晓迪教授课题组提出了一种基于深度学习的近场衍射解码系统,能够以非干涉、非迭代、快速的方式准确读取振幅和相位信息,从而解决了全息数据存储中复振幅调制的关键技术瓶颈。
深度学习与全息数据存储相结合的成功取决于三个关键点。关键点之一是无透镜近场衍射强度检测。无透镜系统和近场距离的选择都是为了保证光场具有一定的衍射效应,使相位变化通过衍射传递到光强分布,同时仍然保留振幅特征。
在仿真和实验中,这种对应关系在一定范围内存在,具体的衍射距离取决于输入编码的空间频率和复杂度等因素。例如,如果编码具有较高的空间频率,则衍射效应更强,近场衍射距离应该更短。第二个关键点是找到幅度和相位之间的特征差异。由于振幅和相位都是从近场衍射强度图中获知的,因此必须有可区分的点以防止它们之间混淆。
研究人员发现,决定振幅学习网络的特征是低频部分的强度分布,而决定相位学习网络的特征是高频部分的相位差模式。这使得相同的近场衍射强度图能够在不受干扰的情况下分别重建振幅和相位。
第三个关键点是不等间隔编码。通常,均匀编码具有较大的编码区间,可以减少编码重构干扰,但在该方法中,均匀区间编码产生的相位差组合是完全相同的,深度学习无法区分相应的衍射特征。因此,非均匀编码可以大大提高样本的多样性,从而使深度学习网络能够准确识别复杂幅度编码。
这项工作不仅在全息数据存储领域有应用,而且对基于深度学习的计算成像的其他领域也有影响。深度学习“黑匣子”物理意义不明确限制了其应用。在全息数据存储领域,可以自由设计编码,为研究对象提供先验知识。因此,通过建立深度学习复幅编解码的评价机制,分析不同编码条件与深度学习解码效率的关系,可以确定哪些编码规则更适合深度学习解码,制定优化策略用于全息数据存储中的复振幅编码,并基于此策略在编码和解码之间迭代优化。这可以为深度神经网络结构的参数赋予结构化的物理函数,为打开深度学习的“黑匣子”打下基础。
免责声明:本文由用户上传,与本网站立场无关。财经信息仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。 如有侵权请联系删除!
-
宝子们,杭州 房子装修完成啦!这次要给大家分享几家设计超赞的装修公司哦。它们各具特色,从空间规划到风格...浏览全文>>
-
欲筑室者,先治其基。在上海,装修房子对于每个业主而言,都是极为关键的一步,然而,如何挑选一家值得信赖的...浏览全文>>
-
2025年以来,联通支付严格贯彻落实国家战略部署,以数字和科技为驱动,做好金融五篇大文章,履行支付为民社会...浏览全文>>
-
良工巧匠,方能筑就华居;精雕细琢,方可打造美家。当我们谈论装修公司时,选择一家靠谱可靠的公司是至关重要...浏览全文>>
-
在当今社会,随着城市化进程的高速推进,建筑垃圾的产生量与日俱增。据权威数据显示,我国每年建筑垃圾产生量超 ...浏览全文>>
-
家人们,在上海要装修,选对公司那可太重要了!古语有云:"安得广厦千万间,大庇天下寒士俱欢颜。"一个温馨的...浏览全文>>
-
近年来,新能源汽车市场发展迅猛,各大品牌纷纷推出各具特色的车型以满足消费者多样化的需求。作为国内新能源...浏览全文>>
-
近年来,随着汽车市场的不断变化和消费者需求的升级,安徽滁州地区的宝来2025新款车型在市场上引起了广泛关注...浏览全文>>
-
随着汽车市场的不断变化,滁州地区的消费者对高尔夫车型的关注度持续上升。作为大众品牌旗下的经典车型,高尔...浏览全文>>
-
在2023年,大众探影以其时尚的设计和出色的性能赢得了众多消费者的青睐。作为一款小型SUV,探影凭借其紧凑的车...浏览全文>>
- 安徽滁州途安L新车报价2022款,最低售价16.68万起,入手正当时
- 小鹏G7试驾,新手必知的详细步骤
- 别克GL8预约试驾,4S店的贴心服务与流程
- 安徽阜阳ID.4 CROZZ落地价全解,买车必看的省钱秘籍
- 淮北探岳多少钱 2025款落地价,最低售价17.69万起现在该入手吗?
- 安徽淮南大众CC新款价格2025款多少钱能落地?
- 淮北长安启源C798价格,最低售价12.98万起现在该入手吗?
- 安徽淮南途锐价格,各配置车型售价全解析
- 蒙迪欧试驾预约,4S店体验全攻略
- 沃尔沃XC40试驾需要注意什么
- 滁州ID.4 X新车报价2025款,各车型售价大公开,性价比爆棚
- 试驾思域,快速操作,轻松体验驾驶乐趣
- 试驾长安CS35PLUS,一键搞定,开启豪华驾驶之旅
- 天津滨海ID.6 X落地价限时特惠,最低售价25.9888万起,错过不再有
- 天津滨海凌渡多少钱?看完这篇购车攻略再做决定
- 安徽池州长安猎手K50落地价,买车前的全方位指南
- 山东济南ID.6 CROZZ 2024新款价格,最低售价19.59万起,现车充足
- 试驾海狮05EV,新手必知的详细步骤
- 生活家PHEV多少钱 2025款落地价走势,近一个月最低售价63.98万起,性价比凸显
- 奇瑞风云A9试驾,新手必知的详细步骤