采样和流水线方法加速大图的深度学习
图是一种由边连接的潜在广泛节点网络,可用于表达和询问数据之间的关系,如社交联系、金融交易、交通、能源网格和分子相互作用。随着研究人员收集更多数据并构建这些图形图片,研究人员将需要更快、更高效的方法以及更强的计算能力,以图神经网络(GNN)的方式对它们进行深度学习。
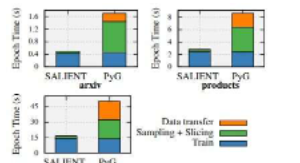
现在,麻省理工学院和IBM研究院的研究人员开发了一种称为SALIENT(SAmpling、sLIcing和数据移动)的新方法,它通过解决计算中的三个关键瓶颈来提高训练和推理性能。这极大地减少了GNN在大型数据集上的运行时间,例如,大型数据集包含1亿个节点和10亿条边。此外,该团队发现,当计算能力从1个增加到16个图形处理单元(GPU)时,该技术可以很好地扩展。这项工作在第五届机器学习和系统会议上进行了介绍。
“我们开始研究当前系统在将最先进的图形机器学习技术扩展到真正的大数据集时所遇到的挑战。事实证明,还有很多工作要做,因为很多现有系统我们主要在适合GPU内存的较小数据集上取得了良好的性能,”麻省理工学院计算机科学与人工智能实验室(CSAIL)的主要作者和博士后TimKaler说。
专家所说的庞大数据集是指像整个比特币网络这样的规模,其中某些模式和数据关系可以阐明趋势或犯规行为。“区块链上有近10亿笔比特币交易,如果我们想在这样一个联合网络中识别非法活动,那么我们将面临如此规模的图表,”共同作者、高级研究科学家兼经理JieChen说。IBMResearch和MIT-IBMWatson人工智能实验室。“我们希望构建一个能够处理这种图形并使处理尽可能高效的系统,因为我们每天都希望跟上生成的新数据的步伐。”
Kaler和Chen的合著者包括JumpTrading的NickolasStathasMEng'21,他在毕业论文中开发了SALIENT;前MIT-IBMWatsonAILab实习生和MIT研究生AnneOuyang;MITCSAIL博士后Alexandros-StavrosIliopoulos;MITCSAIL研究科学家TaoB.Schardl;麻省理工学院电气工程EdwinSibleyWebster教授兼麻省理工学院-IBM沃森人工智能实验室研究员CharlesE.Leiserson。
对于这个问题,该团队在开发他们的方法时采用了面向系统的方法:SALIENT,Kaler说。为此,研究人员实施了他们认为重要的、适合现有机器学习框架的组件的基本优化,例如PyTorchGeometric和深度图形库(DGL),它们是构建机器学习模型的接口。
Stathas说这个过程就像更换引擎来制造一辆更快的汽车。他们的方法旨在适应现有的GNN架构,以便领域专家可以轻松地将这项工作应用到他们指定的领域,以加快模型训练并在推理过程中更快地梳理出见解。该团队确定的诀窍是让所有硬件(CPU、数据链路和GPU)始终保持忙碌:CPU对图形进行采样并准备小批量数据,然后通过数据链路传输这些数据,更关键的GPU正在努力训练机器学习模型或进行推理。
研究人员首先分析了一个常用的GNN机器学习库(PyTorchGeometric)的性能,该库显示可用GPU资源的利用率低得惊人。应用简单的优化,研究人员将GPU利用率从10%提高到30%,相对于公共基准代码,性能提高了1.4到两倍。这种快速基线代码可以在50.4秒内通过算法(一个纪元)对大型训练数据集执行一次完整传递。
为了进一步提高性能,研究人员着手研究数据管道开始时出现的瓶颈:图形采样和小批量准备的算法。与其他神经网络不同,GNN执行邻域聚合操作,该操作使用图中其他附近节点中存在的信息来计算节点的信息——例如,在社交网络图中,来自用户朋友的朋友的信息。
随着GNN中层数的增加,网络必须接触的节点数量可能会激增,超过计算机的极限。邻域采样算法通过选择较小的随机节点子集来提供帮助;然而,研究人员发现,当前的实现速度太慢,无法跟上现代GPU的处理速度。
作为回应,他们确定了数据结构、算法优化等的组合,提高了采样速度,最终仅采样操作就提高了大约三倍,使每个时期的运行时间从50.4秒增加到34.6秒。该团队指出,他们还发现可以在推理过程中以适当的速率进行采样,从而提高整体能源效率和性能,这一点在文献中被忽视了。
在以前的系统中,此采样步骤是一种多进程方法,会在进程之间创建额外的数据和不必要的数据移动。研究人员通过创建一个具有轻量级线程的进程,将CPU上的数据保存在共享内存中,从而使他们的SALIENT方法更加灵活。此外,SALIENT利用了现代处理器的缓存,Stathas说,并行化特征切片,在CPU核心缓存的共享内存中从感兴趣的节点及其周围的邻居和边缘中提取相关信息。这再次将每个时期的总运行时间从34.6秒减少到27.8秒。
研究人员解决的最后一个瓶颈是使用预取步骤在CPU和GPU之间流水线传输小批量数据,这将在需要之前准备数据。该团队计算出,这将最大限度地利用数据链路中的带宽,并使该方法达到完美利用;然而,他们只看到了大约90%。他们发现并修复了一个流行的PyTorch库中的性能错误,该错误导致CPU和GPU之间不必要的往返通信。修复此错误后,该团队使用SALIENT实现了每轮16.5秒的运行时间。
“我认为,我们的工作表明细节决定成败,”卡勒说。“当你在训练图神经网络时密切关注影响性能的细节时,你可以解决大量的性能问题。使用我们的解决方案,我们最终完全被GPU计算瓶颈,这是此类的理想目标一个系统。”
SALIENT的速度是在三个标准数据集ogbn-arxiv、ogbn-products和ogbn-papers100M以及多机设置和不同级别的扇出(CPU为GPU准备的数据量)和跨多种架构,包括最新的最先进的GraphSAGE-RI。在每个设置中,SALIENT都优于PyTorchGeometric,最显着的是在大型ogbn-papers100M数据集上,该数据集包含1亿个节点和超过10亿条边在这里,它在一个GPU上运行时比最初创建的优化基线快三倍这项工作;使用16个GPU,SALIENT的速度提高了八倍。
虽然其他系统的硬件和实验设置略有不同,因此并不总是直接比较,但SALIENT仍然优于它们。在达到类似精度的系统中,代表性的性能数字包括使用一个GPU和32个CPU的99秒,以及使用1,536个CPU的13秒。相比之下,SALIENT使用一个GPU和20个CPU的运行时间为16.5秒,而使用16个GPU和320个CPU的运行时间仅为两秒。
“如果您查看之前工作报告的底线数字,我们的16GPU运行时间(两秒)比之前在此数据集上报告的其他数字快一个数量级,”Kaler说。
研究人员将他们的性能改进部分归因于他们在转移到分布式设置之前为单台机器优化代码的方法。Stathas说,这里的教训是,为了你的钱,“在你开始扩展到多台计算机之前,更有效地使用你拥有的硬件更有意义,”这可以显着节省成本和碳排放可以通过模型训练来实现。
这种新能力现在将使研究人员能够处理和挖掘越来越大的图表。例如,前面提到的比特币网络包含100,000个节点;SALIENT系统可以处理大1,000倍(或三个数量级)的图形。
“在未来,我们不仅会考虑在我们为分类或预测每个节点的属性而实施的现有算法上运行这个图神经网络训练系统,而且我们还想做更深入的任务,比如识别图中的常见模式(子图模式),[这]对于指示金融犯罪可能实际上很有趣,”Chen说。
“我们还想识别图中相似的节点,从某种意义上说,它们可能对应于金融犯罪中的同一个坏人。这些任务将需要开发额外的算法,也可能需要开发神经网络架构。”
免责声明:本文由用户上传,与本网站立场无关。财经信息仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。 如有侵权请联系删除!
-
宝子们,杭州 房子装修完成啦!这次要给大家分享几家设计超赞的装修公司哦。它们各具特色,从空间规划到风格...浏览全文>>
-
欲筑室者,先治其基。在上海,装修房子对于每个业主而言,都是极为关键的一步,然而,如何挑选一家值得信赖的...浏览全文>>
-
2025年以来,联通支付严格贯彻落实国家战略部署,以数字和科技为驱动,做好金融五篇大文章,履行支付为民社会...浏览全文>>
-
良工巧匠,方能筑就华居;精雕细琢,方可打造美家。当我们谈论装修公司时,选择一家靠谱可靠的公司是至关重要...浏览全文>>
-
在当今社会,随着城市化进程的高速推进,建筑垃圾的产生量与日俱增。据权威数据显示,我国每年建筑垃圾产生量超 ...浏览全文>>
-
家人们,在上海要装修,选对公司那可太重要了!古语有云:"安得广厦千万间,大庇天下寒士俱欢颜。"一个温馨的...浏览全文>>
-
近年来,新能源汽车市场发展迅猛,各大品牌纷纷推出各具特色的车型以满足消费者多样化的需求。作为国内新能源...浏览全文>>
-
近年来,随着汽车市场的不断变化和消费者需求的升级,安徽滁州地区的宝来2025新款车型在市场上引起了广泛关注...浏览全文>>
-
随着汽车市场的不断变化,滁州地区的消费者对高尔夫车型的关注度持续上升。作为大众品牌旗下的经典车型,高尔...浏览全文>>
-
在2023年,大众探影以其时尚的设计和出色的性能赢得了众多消费者的青睐。作为一款小型SUV,探影凭借其紧凑的车...浏览全文>>
- 安徽滁州途安L新车报价2022款,最低售价16.68万起,入手正当时
- 小鹏G7试驾,新手必知的详细步骤
- 别克GL8预约试驾,4S店的贴心服务与流程
- 安徽阜阳ID.4 CROZZ落地价全解,买车必看的省钱秘籍
- 淮北探岳多少钱 2025款落地价,最低售价17.69万起现在该入手吗?
- 安徽淮南大众CC新款价格2025款多少钱能落地?
- 淮北长安启源C798价格,最低售价12.98万起现在该入手吗?
- 安徽淮南途锐价格,各配置车型售价全解析
- 蒙迪欧试驾预约,4S店体验全攻略
- 沃尔沃XC40试驾需要注意什么
- 滁州ID.4 X新车报价2025款,各车型售价大公开,性价比爆棚
- 试驾思域,快速操作,轻松体验驾驶乐趣
- 试驾长安CS35PLUS,一键搞定,开启豪华驾驶之旅
- 天津滨海ID.6 X落地价限时特惠,最低售价25.9888万起,错过不再有
- 天津滨海凌渡多少钱?看完这篇购车攻略再做决定
- 安徽池州长安猎手K50落地价,买车前的全方位指南
- 山东济南ID.6 CROZZ 2024新款价格,最低售价19.59万起,现车充足
- 试驾海狮05EV,新手必知的详细步骤
- 生活家PHEV多少钱 2025款落地价走势,近一个月最低售价63.98万起,性价比凸显
- 奇瑞风云A9试驾,新手必知的详细步骤